
ВВЕДЕНИЕ
Во время написания любого автотеста мы в большей степени будем работать с веб элементами на наших страницах. Для понимая как их находить сначала нужно вкратце разобраться что такое DOM.
DOM (от англ. Document Object Model — “объектная модель документа”) — это независящий от платформы и языка программный интерфейс, позволяющий программам и скриптам получить доступ к содержимому HTML, XHTML и XML документов.
Если провести аналогию с веб сайтами, то любая его страница это HTML документ, который имеет древовидную структуру, а программой является наш браузер, который умеет приводить наши документы к тому виду, что мы привыкли.
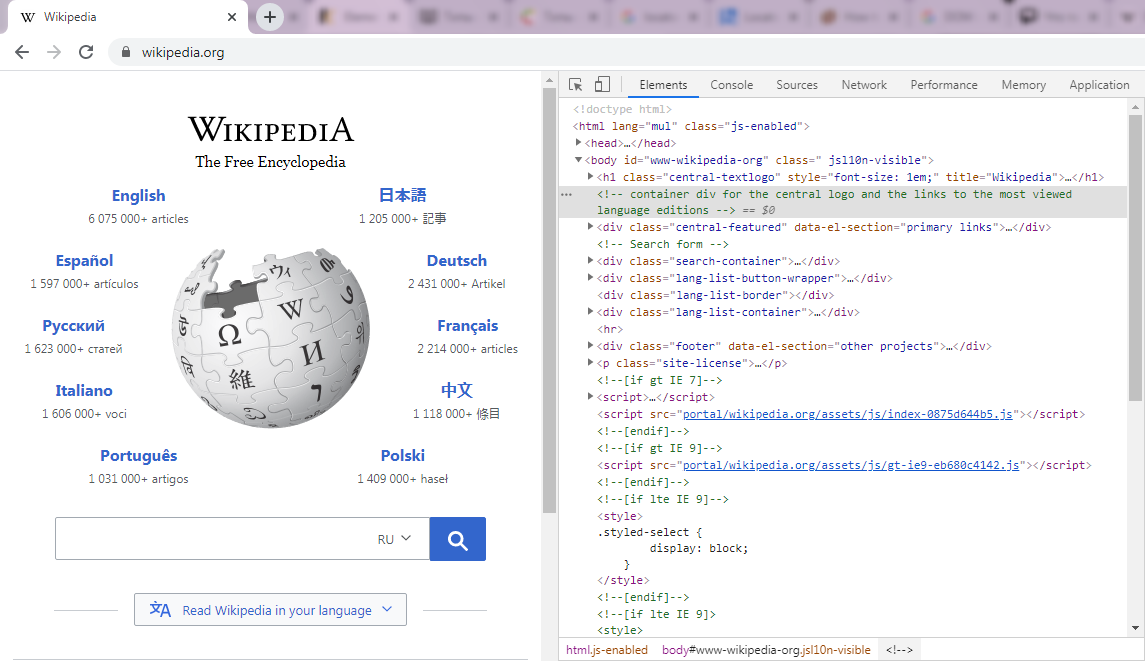
Чтобы увидеть HTML документ любой страницы нужно в браузере нажать на клавишу F12, для вызова консоли и выбрать вкладку Elements:
ЛОКАТОРЫ
Далее для работы с DOM объектами или в нашем случае веб элементами нам необходимо их точным образом определить (найти на странице). В этом нам помогут локаторы, которые являются командой в виде пути по нашему дереву к конкретному элементу (тегу в нашем HTML документе).
IWebElement elementName = driver.FindElement(By.LocatorStrategy("LocatorValue"));
LocatorStrategy – может быть любым из следующих значений:
- Id
- Name
- ClassName
- TagName
- LinkText
- PartialLinkText
- XPath
- CssSelector
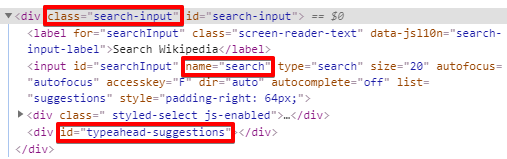
Первые 3 (Id, Name, ClassName) являются значением соответствующих атрибутов внутри наших тегов:
TagName – как видно с названия мы можем искать один или несколько элементов по названию конкретного тега. Например чтобы найти все ссылки на нашей странице мы можем использовать другой webdriver метод FindElements, который возвращает нам в виде списка не один элемент, а все:
ReadOnlyCollection links = driver.FindElements(By.TagName("a"));
Остались 2 более сложных типа локаторов XPath и CssSelector, с помощью которых мы можем указывать полный или относительный путь по тегам, чтобы была возможность более точно определить элемент. Использовать эти типы нужно, когда у наших элементов нету уникальных значений атрибутов (id, class…) или текста.
Какой из них лучше использовать? По некоторым замерам CssSelectors имеют более высокую производительностью.
Также важным различием между CSS и XPath локаторами является то, что используя XPath, мы можем производить перемещение как в глубину DOM иерархии, так и возвращаться назад. Что же касается CSS, то тут мы можем двигаться только в глубину. Это значит, что с XPath можем найти родительский элемент, по дочернему.
КАК ПОСТРОИТЬ XPATH И CSSSELECTOR?
Поскольку наш автотест мы запускаем в Google Chrome, то и для поиска элементов будем использовать именно его.
Загружаем нужную нам страницу: https://www.wikipedia.org/
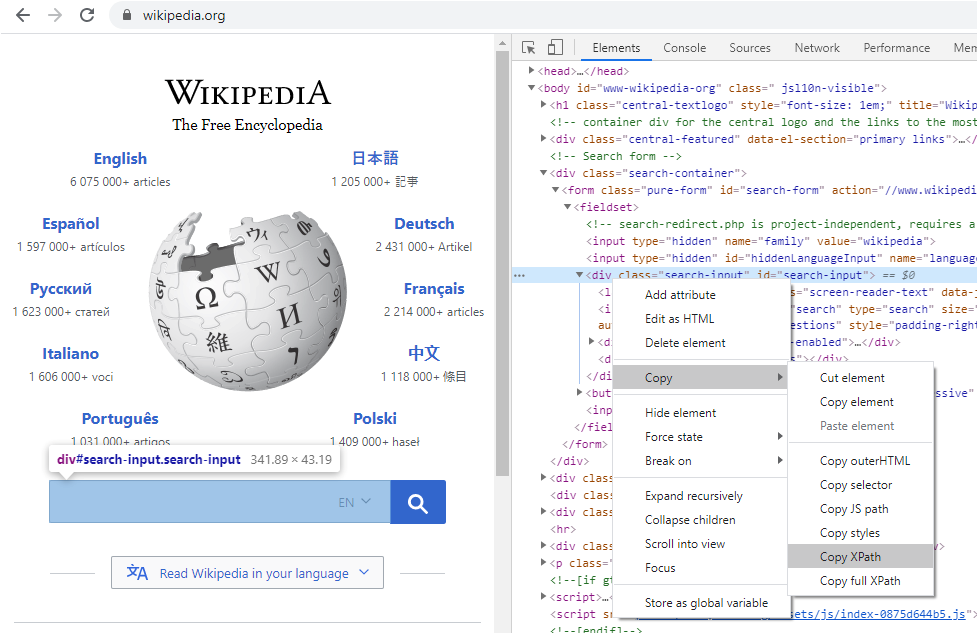
Нажимаем правой клавишей мыши на нужный нам элемент и вызываем контекстное меню Inspect. У нас в браузере откроется дополнительное окно (которое также можно вызвать нажатием клавиши F12) с подсвеченным в HTML документе элементом. Далее вызываем контекстное меню у нашего элемента -> Copy -> Copy XPath (или Copy selector):
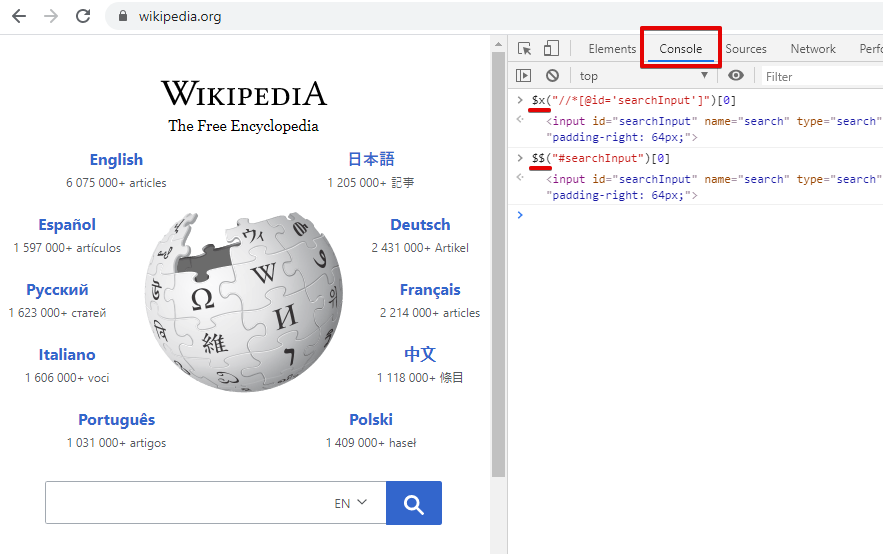
Теперь нам нужно проверить наш локатор и при необходимости сократить его или отредактировать. Для этого в дополнительном окне переходим во вкладку Console и для Xpath вставляем скопированный путь в команду $x(“value”), а для CssSelector $(“value”):
Важно понимать, что в данном случае у нас указан не полный путь в дереве (от тега body и до нашего элемента), а относительный (сокращенный или без звеньев, которые не влияют на сам поиск), что позволяет быть менее зависимыми в случаях, когда HTML документ изменяется в процессе разработки.
Приведу несколько самых распространенных примеров построения локаторов:
CSS локаторы
Абсолютный путь:"html body div div form input"
Относительный путь: "input"
Поиск непосредственного дочернего элемента: "div > a"
Поиск дочернего элемента любого уровня: "div a"
Поиск по ID элемента: "#username"
Поиск по классу: ".classname"
Поиск по значениям атрибутов html тегов: "img[alt='Previous']"
Поиск по названию атрибутов: "img[alt]"
Поиск по началу строки: "header[id^='page-']"
Поиск по окончанию строки: "header[id$='page-']"
Поиск по частичному совпадению строки: "header[id*='page-']"
XPath локаторы
Абсолютный путь: "html/body/div/div/form/input"
Относительный путь: "//input"
Поиск непосредственного дочернего элемента: "//div/a"
Поиск дочернего элемента любого уровня: "//div//a"
Поиск элемента по тексту: ".//*[text()='Первая ссылка']/.."
Поиск по значениям атрибутов: "//input[@id='username']"
Поиск по названию атрибутов: "img[@alt]"
Поиск родительского элемента: "//input[@id='username']/.."
С построением разнообразного пути и разницей между типа локаторов можно ознакомиться в сравнительной таблице по ссылке или в сгруппированной схеме.